Why AI readiness is an information architecture problem — and what it means for records professionals
Artificial intelligence is moving into the enterprise faster than most organisations can comfortably absorb. That pace is creating excitement, concern, confusion and – in some cases – a fair bit of panic. AI is changing how people search, summarise, classify, analyse and act on information, and that naturally places pressure on every business function responsible for managing information properly.
For records professionals, this is a particularly important moment. Records teams have spent years trying to help organisations manage information with more discipline, more consistency and more accountability. This work has often been difficult. Not because the principles are wrong, but because records management has too often been treated as an administrative function rather than a strategic business capability.
AI has shifted this conversation by pushing organisations to adopt it quickly, which has brought existing information problems to light. Issues such as poor classification, weak metadata, uncontrolled repositories, unclear ownership, inconsistent retention, duplicate documents, missing audit trails, legacy systems, unmanaged file shares, uncontrolled SharePoint sites, and outdated content have always been present. AI did not create these problems, but it has made them much harder to overlook.
This is where records professionals are now being pulled into a much bigger discussion. Enterprise AI is not just a tool selection problem. It is not simply a question of whether an organisation should use Microsoft Copilot, ChatGPT Enterprise, Claude, Gemini, a local model, or a custom-built agent. Those choices matter, but they sit on top of a much more important foundation.
The real question is whether the organisation's information architecture is ready for AI to safely and usefully operate within it.
AI Does Not Remove the Need for Records Management
One of the more interesting assumptions around AI is that it will somehow reduce the need for structured information management. The thinking seems to be that because AI can search, summarise and interpret information, the underlying structure matters less. Making this assumption is dangerous.
AI may make information easier to access, but it does not automatically make that information reliable, authoritative, current, appropriate or safe to use. A model does not inherently know which policy is the approved version, which document has been superseded, which file contains sensitive personal information, which record is subject to retention rules, or which user should be prevented from seeing particular content.
Those controls do not appear by magic; they must be designed into the architecture. This is why records management becomes more important, not less. As AI systems begin to sit across enterprise information, they need governed data sources, clear permissions, reliable context, accurate classification and defensible lifecycle rules. Without that, AI simply becomes a faster way to surface confusion.
In traditional systems, poor information governance might slow people down. In AI-enabled systems, poor information governance can be scaled. It can be summarised, repackaged, retrieved, reused and acted upon at speed. That is where the risk changes character.
The Shift From Stored Information to Active Information
Historically, many organisations have treated records as something that sits behind the work. A decision is made, an email is sent, a document is approved, a transaction occurs — and the record is captured or stored as evidence of that activity. This model still matters, but AI is changing the role information plays inside the organisation.
Information is no longer just stored for future retrieval. Increasingly, it is being used actively inside intelligent workflows. It may be indexed into a knowledge base, embedded into a vector store, retrieved through a RAG (Retrieval-Augmented Generation) pipeline, summarised by an AI assistant, used to support a decision, or passed into an agent that performs an action in another system. The effect of this change is palpable.
When information becomes active, the organisation needs a much clearer understanding of what that information is, where it came from, how it has been transformed, whether it is still current, and whether it should be used for the purpose being requested.
This is where records management and enterprise architecture start to overlap more heavily. The question is no longer simply, "where do we store the record?". It becomes "how does trusted information move through intelligent systems without losing control, context or accountability?". Most organisations are not yet asking this question clearly and often enough.
RAG Was a Good Start, But It Was Never the Whole Answer
Retrieval-Augmented Generation (RAG) became one of the first serious enterprise responses to the limitations of large language models. Rather than relying only on a model's general training, RAG allows an organisation to retrieve relevant internal information and provide it as context to the AI system. In simple terms, the AI gets a better brief before it answers.
That has been a useful step forward. It has helped organisations see how AI can work with their own information rather than generating broad, generic responses. But RAG also introduced a new set of architecture and governance questions that are not always fully understood.
To make RAG work, information normally needs to be extracted, cleaned, chunked, enriched with metadata, converted into embeddings, stored in a retrieval layer and then retrieved at the right time for the right user. Each of those steps can affect meaning, context, security and reliability.
A source document may be authoritative in its original repository, but what happens when it is split into chunks? What metadata is preserved? What relationship is maintained between the retrieved passage and the original record? What happens when the source document is updated, superseded or disposed of? How does the organisation prove which information was used to support an AI-generated answer?
These are not minor technical details. They are central to whether the AI system can be trusted.
The National Archives of Australia has recognised that AI creates new information management challenges and provides guidance on identifying and managing Commonwealth records created by, or relating to, AI technologies. The State Records Office of Western Australia has also noted that records created or affected by AI should form part of an organisation’s broader information and records management strategy.
That should be a signal to every organisation adopting AI. The AI system itself is not the only thing that matters. The information it uses, creates, changes, summarises and influences may also need to be managed as part of the recordkeeping environment.
Vector Stores Create a New Kind of Information Asset
Vector stores are one of the more interesting areas for the records industry because they do not look like traditional records systems. They do not look like a database that most business users would recognise. They do not look like an EDRMS. They do not look like a folder structure. They often do not even contain the original document in a human-readable format.
But they may still hold a representation of organisational knowledge and this definitely matters.
When information is converted into embeddings and stored in a vector database, the organisation has created a new information asset that can influence retrieval, reasoning and AI-generated responses. It may not be the official record, but it can affect what the AI system finds, how it compares information, and what it presents back to the user.
That creates some uncomfortable but necessary questions for records professionals and enterprise architects.
Is the vector store simply a technical index, or is it part of the organisation’s information environment? Does it need lifecycle management? Does it need access controls aligned to the source systems? Does it need to be rebuilt when source records change? What happens when a record reaches the end of its retention period but its embedded representation still exists in a retrieval layer? How does an organisation explain the basis of an AI-generated response if the retrieval layer cannot be properly audited?
These questions do not have simple universal answers. They will depend on how the architecture is designed and how the organisation uses the system. But ignoring them would be a mistake.
The records industry does not need to force old terminology onto new technology. However, it does need to recognise when new technical components become part of how organisational evidence, knowledge and decisions are shaped.
AI Agents Increase the Stakes
The first wave of enterprise AI adoption has largely focused on assistance. Ask a question. Summarise a document. Draft an email. Extract key points. Search across a body of information. From there, the next stage is action.
AI agents are being designed to interact with systems, trigger workflows, update records, classify content, prepare responses, search repositories, create tasks, monitor events and make recommendations based on changing information. Once AI starts acting, the architecture requirements become much more serious.
An AI assistant that gives a poor answer is one type of risk. An AI agent that acts on poor information, applies the wrong classification, updates the wrong field, sends the wrong response, or retrieves information the user should not have seen.
This is where the records industry needs to pay attention to technologies such as APIs, workflow engines, Model Context Protocol, event-based architecture, identity controls, audit logging, retrieval systems and permission-aware agents. These are not just technical tools for developers. They are becoming the rails that determine how AI systems interact with organisational information.
An enterprise AI agent needs clear boundaries. It needs to know which systems it can access, which actions it can perform, which decisions require human review, which records are authoritative, which information is sensitive, and which events must be logged. It needs to operate within the organisation's governance model, not outside it.
This is why AI architecture cannot be separated from records governance, privacy, cyber security and information management. The agent may be technical, but the consequences are organisational.
Shadow AI Shows What Happens When Architecture Falls Behind
One reason this issue is urgent is that AI adoption is not waiting for perfect governance. Staff are already using AI tools. Some are approved; some are not. Some are visible to IT; others sit completely outside normal oversight.
This is not a new pattern. When official systems are too slow, too difficult or too disconnected from daily work, people create workarounds. AI simply makes those workarounds more powerful.
A staff member may paste content into an external AI tool to summarise it, which could generate a response from sensitive information. Some staff may rely on an AI-generated summary without checking whether it captured the full context accurately. They may use a tool that stores prompts or responses in a way the organisation has not assessed.
From the user's perspective, this feels like productivity. From an organisational perspective, it may create unmanaged information, unmanaged disclosure, unmanaged records and unmanaged risk.
This is why "just block it" is not a long-term answer. The pressure to use AI is too strong, and the potential value is real. People are not using AI only because it is fashionable; they are using it because they are overloaded, under pressure, and looking for faster ways to get work done.
The better response is to build safer pathways. That means giving staff approved AI tools, governed data sources, clear guidance, usable workflows and architecture that makes the right choice easier than the risky workaround.
Prompt Libraries, Skills and Agent Instructions Need Attention
There is another part of the AI architecture conversation that records professionals should be watching closely: the rise of prompt libraries, reusable skills, agent instructions, markdown knowledge files, internal wikis and curated AI guidance.
At first glance, these may seem informal. A prompt might look like a simple instruction. A skill file might look like a small operating procedure. A markdown knowledge base might look like a lightweight internal wiki. But some of these artefacts will have real operational power.
If an approved agent instruction determines how an AI system classifies records, searches sensitive data, drafts responses, escalates issues, interprets policy or supports compliance decisions, then that instruction is no longer casual working material. It is part of the system's behaviour. Questions about governance will then be raised.
Who approved the instruction? Who can change it? Is there version control? Is it tested before release? Is there a record of why it changed? Does it align with policy? Does it need retention? Does it need to be auditable if a decision is challenged?
The same applies to curated AI knowledge files. Many organisations are beginning to create clean, structured, human-readable knowledge sources to help AI systems work better. These may be more useful to an AI model than a messy repository of old documents. They may also be easier for humans to review and maintain.
If those files become the source of truth for an AI-enabled workflow, they need to be governed accordingly. They may not look like traditional records, but they may influence business decisions in a very direct way.
The Records Industry Has an Opportunity to Step Forward
The records industry is under pressure, but this should not be seen only as a threat. It is also an opportunity to reposition records management as a core part of enterprise AI readiness.
For years, records professionals have understood that information has consequences. Poor information creates poor decisions. Uncontrolled information creates risk. Hidden information creates exposure. Over-retained information creates cost and liability. Missing records create accountability problems, which is not a new issue. What is new is the speed and scale at which AI can interact with that information.
That gives records professionals a stronger reason to be involved earlier in technology planning. Not after the AI pilot has already been built. Not after the vendor has already indexed the data. Not after the organisation has already rolled out an AI assistant with unclear access boundaries. Records management needs to be part of the architecture conversation from the beginning.
That does not mean records teams need to become AI engineers. It means they need to understand enough about AI architecture to ask better questions and shape better design decisions.
Which repositories are being indexed? Which records are authoritative? Which metadata fields matter? How are permissions enforced? How are prompts and agent instructions controlled? How are AI-generated outputs captured? How are retrieval results linked back to source material? How are retention and disposal obligations maintained across derived AI assets?
This Is Bigger Than AI Governance
There is a lot of discussion in the market about AI governance. Some of it is useful, and some of it is polished language wrapped around thin operational thinking.
The risk is that AI governance becomes another layer of documents, frameworks and diagrams that look impressive but do not change how systems work.
Governance needs to reach into the systems, workflows, permissions, logs, repositories, indexes, knowledge bases and agent behaviours that determine how AI operates in practice. Otherwise, the organisation may have a governance framework that says the right things while the actual AI environment behaves in ways nobody can properly explain.
This is where records management can add real value. Records thinking is naturally concerned with evidence, context, authority, lifecycle, accountability and defensibility. Those are exactly the qualities enterprise AI will need if it is to move beyond experimentation and into trusted business use.
The future is not records management versus AI. Records management is part of the AI operating environment.
Final Thoughts
AI is not replacing the need for records management. It is exposing why records management matters.
The organisations that succeed with enterprise AI will not be the ones that simply buy the newest tool or connect a model to a pile of documents. They will be the ones who understand the information architecture underneath. They will know what they hold, where it resides, who can access it, how it is classified, whether it is current, how it should be retained, and whether it can be safely used by an AI system. Whilst not glamourous, it is foundational
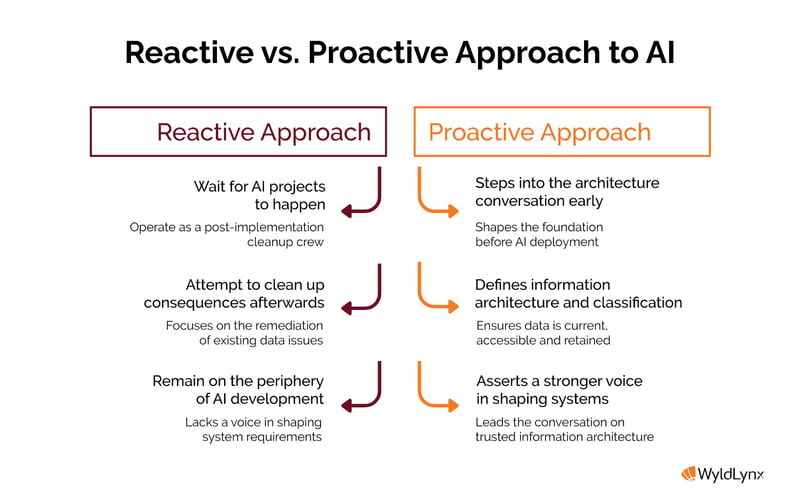
The records industry now has a choice. It can wait for AI projects to happen around it and then try to clean up the consequences afterwards. Or it can step into the architecture conversation early – bringing the questions that organisations will increasingly need to answer.
Not all the answers are clear yet, but our direction can be. Enterprise AI needs a trusted information architecture. Records professionals should have a stronger voice in shaping what that looks like – and that conversation is already well underway.